Asset criticality and risk are primary among the many factors that must be considered to appropriately manage valves throughout their lifecycle
Asset strategies usually define how assets will be treated in the different phases of an asset lifecycle, from acquisition through disposition, and also typically will include corrective action for deficiencies. For example, valves not yet installed will have a set of engagement strategies that differ from in-service valves, as well as decommissioned valves prepped for sale, versus disposition of the asset (Figure 1).

FIGURE 1. Whether dealing with brand-new valves, critical in-service valves, uninstalled spares or decommissioned valves, it is important to specify the best plan to keep valves well-maintained
On the other hand, preventative maintenance (PM) strategies are a subset of asset strategies that focus specifically on failure prevention — this includes filter replacements, visual inspections, oil changes and analysis, vibration analysis and the resulting interventions to forestall a decline in performance. Valve PM strategies and their relationship to overall asset strategies are the focus on this article.
Both asset and PM strategies are influenced and informed by several factors in an asset portfolio, listed below. The most important place to start is considering an asset’s criticality and risk rankings, because these dictate the focus of efforts more than any other factors.
- Criticality (generally static)
- Risk rankings (will change quickly or slowly, depending on failure type)
- Asset condition
- How assets fail (failure modes)
- Overall design and interconnectedness
- Redundancies
- Mandated level of service
- Operational philosophy
Asset criticality informs strategy
Asset criticality will influence the PM strategies (the “what” and “how often”) and the degree to which intervention must happen (“how much” and “how fast” one responds).
Any criticality and risk analysis results should direct focus to the most important assets — those with the highest risk or highest criticality. A new, highly critical valve can quickly become a high risk if it is neglected, and such a high-risk asset can greatly jeopardize plant objectives. Low-risk assets can be deferred or assigned a run-to-failure designation.
Intervention strategies based in part on criticality are often broken into three broad categories where the asset’s criticality ranking will inform the strategy, described below.
- High-criticality valve assets can never go out of service without sufficient lead time to plan for and supplement the outage
- Medium-criticality valve assets usually require sufficient lead time to minimize outages
- Low-criticality valve assets require awareness that the asset is out of service (failed) and a suitable intervention will be planned as time permits
High-criticality asset strategies. For these valves, asset performance can never fall below a certain level — their performance is essential or critical. High-criticality assets should never fail without prior knowledge and planning. These valve assets need an appropriate level and type of monitoring to understand what is happening to the asset well before an impending failure, in order to allow enough time to plan and schedule a suitable intervention. This may require online monitoring or very frequent in-person condition monitoring of dominant failure modes and frequency of valve failure. It may also require frequent PM routines to maintain the asset in excellent working condition to meet the operational requirements. A suitable intervention may require immediate action, such as the staging of supplemental equipment to carry the lost load or finding alternate means of meeting service levels.
Medium-criticality asset strategies.These valve assets can only be out of service for a short period of time, otherwise mitigation of resulting issues might be necessary. While their performance is important to the overall facility or process objectives, their outage will not endanger the level of service targets in the short-term. In this case, sufficient monitoring is required to plan for the outage and schedule it accordingly, so that the outage occurs within an acceptable timeframe.
Low-criticality asset strategies.These valve assets can be run to failure and repaired at will and should not be on any remote or automated monitoring program. Typical examples of this type of equipment are non-essential valves, such as ancillary valves, non-process-central valves, secondary support-system valves, and even certain bypass valving. Repair is made to these assets when convenient.
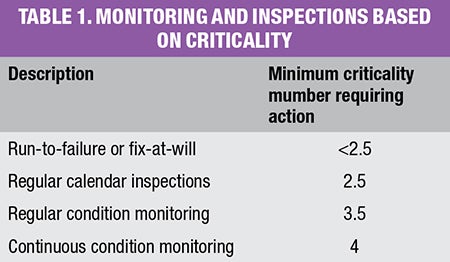
Based on a criticality ranking from 0 to 5 (where 5 is most critical), Table 1 shows an example of a typical monitoring and inspection table that might be used at a processing facility. Anything with a criticality ranking over 4 requires continuous monitoring.
Asset condition
Traditionally, asset condition has been seen as the single most important driver of strategies. While condition plays a part insofar as it influences short-term risk of failure, it must be used cautiously, since it is not the only influence on risk of failure. Much more broadly, condition drives the specific need for repair, not necessarily the strategy or priority, and this is an important distinction. Broken low-criticality valves are a lower priority than a high-criticality valve about to fail.
Failure modes and degradation
A failure mode refers to the ways an asset can break down or fail. The ways an asset fails depends on its components. For maintenance considerations, an asset is actually just a collection of failure modes to be managed. If it is made of electronic parts, then electronic failures apply. If it is largely mechanical and dynamic (rotating, for example) then failures related to the bearings, shafts and seals also apply. To illustrate this, consider a large, motorized flow-control valve that contains many components. Tracking one of the essential components over time, like a bearing, provides good decision support for an appropriate lifecycle strategy. Figure 2 illustrates the condition profile of a bearing over time. The degradation of a bearing is often marked by an increase in torque.
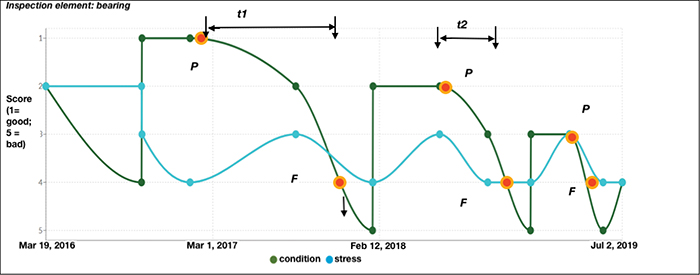
FIGURE 2. This chart shows the condition profile of a bearing over time. The bearing’s degradation can be evaluated based on changes in the torque
In Figure 2, the declining mean time between failure (MTBF), marked by the shorter intervals, is as important as the level of performance achieved after each refurbishment. A declining performance after each restoration and decreasing service interval together may indicate that the asset is nearing the end of its useful life. It may be too expensive to maintain, or may be falling below minimum in-service performance requirements. The stress scoring, a reflection of the operating context and illustrated by the light blue line in Figure 2, offers clues to the decline.
The components that fail (bearings, in this case) and the rate at which they fail (days to weeks) greatly influence the strategy to employ. This is illustrated in the P–F part of the curve in Figure 2, and illustrates the point at which a failure potential is detected (P), and the point at which the asset or component has failed (F). See Nowlan and Heap for their discovery and discussion on this topic [1]. In contrast to bearings, valve body coatings have a more linear failure curve and a far slower rate of failure, often on the order of years.
Inspections need to occur frequently enough to avoid missing the decline (P) once it starts. Assuming an inspection occurs prior to any noticeable degradation, the next inspection must occur at a point on the declining curve that leaves enough time to intervene prior to F, if failure is not an option. This would be the inspection at the end of time period t 1 in Figure 2.
The optimal inspection period will be determined over time and will be based on the valve asset characteristics and the local context. It may be adjusted over time given the changes in a component’s failure-curve time period. This adjustment on shortened failure curves is illustrated in Figure 2 with t2 is shorter than t1.
Critical dynamic rotating assets, such as motorized control valves, pumps or compressors, should be inspected with sufficient frequency to be approximately one-half to one-third of the failure-curve interval to allow enough time to intervene, plan, mitigate and repair the asset without loss of service. This may not be possible with failure degradation curves on the order of days, in which case, any degradation in performance should trigger a work order.
Consider asset operating context
PM strategies will also be influenced by the service status of a valve using the following considerations:
- Lead versus installed bypass
- Rarely turned on or rotated
- Under high stress, such as exposure to waterhammer or cavitation, for example
The degree of usage versus its static state (no active use) influences how often an asset should be both inspected or require routine preventative maintenance. As an example, PM schedules should differ for assets in lead versus lag versus installed spare roles, with schedules ranging from aggressive monitoring and exercising to only occasional monitoring and exercising. Furthermore, installed spares versus the on-shelf spare would also likely have different PM schedules, the latter mostly involving corrosion prevention during storage. This is further modified by the stress the asset experiences, which may include:
- Frequent stopping and starting of motors, as opposed to occasional but continuous operation
- Temperature swings
- Environmental exposure
- General neglect
- Waterhammer
Identical assets experiencing significantly different levels of stress should have different inspection and PM schedules. Importantly, the specific stress will emphasize certain PM methodologies or type of monitoring to identify specific failures the asset manifests due to the load conditions.
Static valves, or valves never exercised, is a designated operating context that should be avoided when compared to a regularly exercised valve program. While exercising valves does introduce a failure mode of “wear” on mated parts and could potentially drive the valve to a failed state eventually, it does, however, provide a window into a valve’s condition (even a declining condition), which is better than the alternative. A valve never exercised is an unknown quantity, and raises many questions for operations teams:• Will the valve close if required or will it be seized?
• Will it seat properly if it does close most of the way?
• Is there corrosion or particulate matter buildup interfering with proper operation?
Similarly, any single-point-of-failure valves must be on a suitable condition-monitoring program to assure proper operation when required.
Cross-connection opportunities
Systems are a collection of assets grouped together to deliver on a primary function of that system — pumping liquid from location A to location B at a defined rate without leaking.
In some cases, a system may have a high redundancy of assets performing the same role, sometimes with substantial overcapacity, and may be sufficiently cross-connected via pipes and valves to offer significant increases in operational resilience. In other cases, a system may have very limited capacity to withstand upset due to a single-service asset, a single-point-of-failure valve, or no cross-valving of the systems. When there are redundant assets, the cross-connection to backup assets can not only provide a high degree of assurance of service delivery, but will also reduce asset criticality compared to a single-asset configuration. As such, a less aggressive inspection cycle can be adopted, sometimes even to the point of permitting an asset to fail with little or no advance knowledge.
Example of network valve strategies. Table 2 gives a general guide for PM strategies for network valves. This set of strategies was developed with a client for their network valves following a comprehensive criticality and risk review, based on the equipment considerations below:
• Regular valve exercise program (all valves over 2 in. in diameter)
• Sleeve valves: regular monthly debris inspection and clear-out
• Shutoff valves greater than 12 in. in diameter: corrective action based on torque

Influence of runtime philosophy
PM strategies are also influenced by runtime philosophies, either favoring an unequal runtime mode of redundant assets or equal runtime mode of the same assets. The preferred operating mode will influence the asset management strategy. Equal runtime will generally warrant more monitoring of the valves and direct the choice of tools to catch detectable failure modes much earlier in the failure cycle. Equal runtime often results in all assets failing at around the same time, which more significantly affects operations than a single asset outage. Considerations include the number of shelf spares and parts, the need for identical assets, large short-term rehabilitation costs to refurbish all at once at the annual turnaround versus the more discrete and smaller costs spread over the year for unequal runtime mode.
In summary
Asset strategies and PM strategies are influenced by and informed by several factors in an asset portfolio, including lifecycle stage, the criticality and risk rankings, asset condition, the valve’s failure modes, overall process interconnectedness and redundancies, mandated level of service and operational philosophy. Each must be considered to appropriately manage the valves — not too much or too little, in the right way at the right time, and with the right discovery tools. ■
Edited by Mary Page Bailey
Reference
1. Nowlan, F. S. and Heap, H. F., Reliability-Centered Maintenance, Defense Technical Information Center, December 1978, https://apps.dtic.mil/sti/pdfs/ADA066579.pdf.
Author
 Tacoma Zach is co-founder and CEO of MentorAPM (2416 E Goldenrod St., Phoenix, AZ 85048; Phone: 602-492-6212). Having spent most of his career in the operation and management of both municipal and industrial water and wastewater operations, he has a great deal of experience in the application of asset-management best practices, risk management and ISO 55000 standards for water and wastewater utilities. He is the author of the book “Criticality Analysis Made Simple,” and speaks frequently at leading asset-management conferences. He holds B.S.Ch.E. and M.S.Ch.E. degrees from the University of Toronto and is a licensed Professional Engineer in Ontario, Canada.
Tacoma Zach is co-founder and CEO of MentorAPM (2416 E Goldenrod St., Phoenix, AZ 85048; Phone: 602-492-6212). Having spent most of his career in the operation and management of both municipal and industrial water and wastewater operations, he has a great deal of experience in the application of asset-management best practices, risk management and ISO 55000 standards for water and wastewater utilities. He is the author of the book “Criticality Analysis Made Simple,” and speaks frequently at leading asset-management conferences. He holds B.S.Ch.E. and M.S.Ch.E. degrees from the University of Toronto and is a licensed Professional Engineer in Ontario, Canada.